





1. 请求网页数据
1.1 urllib3库
urllib3.request(method,url,fields=None,headers=None,**urlopen_kw)

例子:
import urllib3 # 发送请求实例 http = urllib3.PoolManager() # 网址 url='http://www.tipdm.com/tipdm/index.html' # 请求头 head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'} # 超时时间 tm = urllib3.Timeout(connect=1.0, read=3.0) # 重试次数和重定向次数设置并生成请求 rq = http.request('GET', url=url, headers=head, timeout=tm, retries=5, redirect=4) print('服务器响应码:', rq.status) print('响应实体:', rq.data.decode('utf-8'))
1.2 requests库
requests.request.method(url,**kwargs)

例子
import requests url = 'http://www.tipdm.com/tipdm/index.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE' } rqq = requests.get(url,headers=headers) rqq.encoding = 'utf-8' print('实体:', rqq.text)
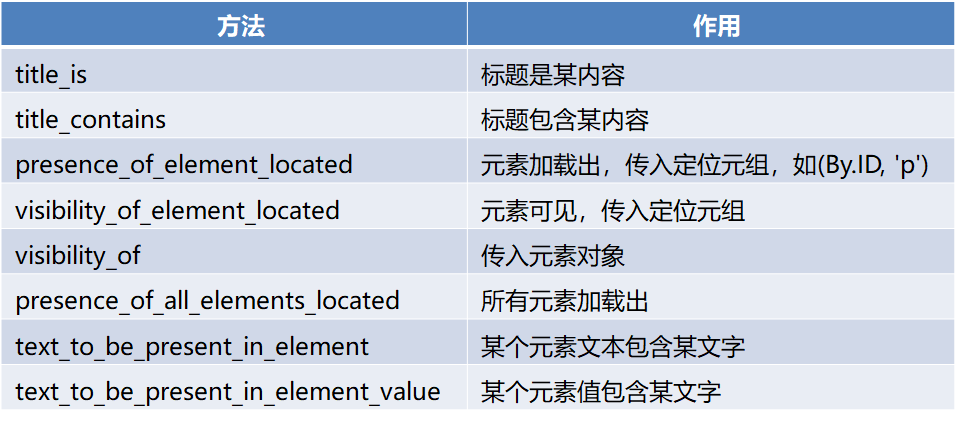
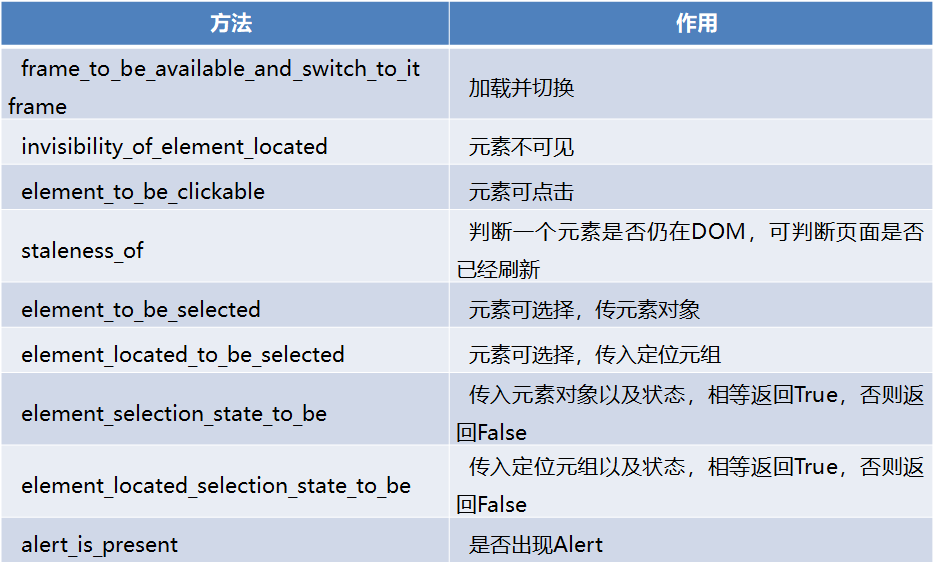
1.3 selenium库
注意:
Selenium Webdriver提供两种类型的等待——隐式和显式。显式的等待使网络驱动程序在继续执行之前等待某个条件的发生。隐式的等待使WebDriver在尝试定位一个元素时,在一定的时间内轮询DOM。在爬取“http://www.ptpress.com.cn/shopping/index”网页搜索“Python编程”关键词过程中,用到了显示等待,本节主要介绍显示等待。显式等待是指定某个条件,然后设置最长等待时间。如果在这个时间还没有找到元素,那么便会抛出异常,在登录“http://www.ptpress.com.cn/shopping/index”网页等待10秒。
示例:
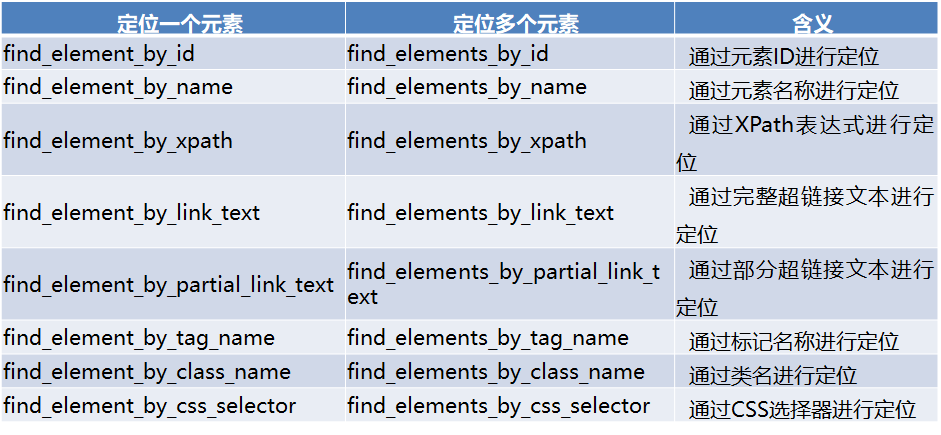
from bs4 import BeautifulSoup import pandas as pd from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC # 初始化驱动 driver = webdriver.Chrome() driver.get("https://www.ptpress.com.cn/search") wait = WebDriverWait(driver, 10) before = driver.current_window_handle # 获取搜索框输入域 input_text = driver.find_element_by_css_selector("#searchVal") # 将要搜索的数据传入页面输入框 input_text.send_keys("python") # 获取搜索按钮 serch_btn = wait.until( EC.element_to_be_clickable( (By.CSS_SELECTOR, "#searchBtn") ) ) # 生成页面按钮点击事件 serch_btn.click() # driver.window_handles # 得到相应的页面 html = driver.page_source html # 解析页面,获取目标数据 soup = BeautifulSoup(html,"lxml") books = soup.select(".book_item>a") hrefs = ["https://www.ptpress.com.cn"+i["href"] for i in books] imgUrls = [i.select("div>img")[0]["src"] for i in books] names = [i.select("p")[0].text for i in books] data = pd.DataFrame({"name":names,"imgUrl":imgUrls,"href":hrefs}) data # 关闭驱动 driver.close()
2. 解析网页
2.1 re库
import re
example_obj = "1. A small sentence. - 2. Another tiny sentence. "
re.findall('sentence',example_obj)
re.search('sentence',example_obj)
re.sub('sentence','SENTENCE',example_obj)
re.match('.*sentence',example_obj)
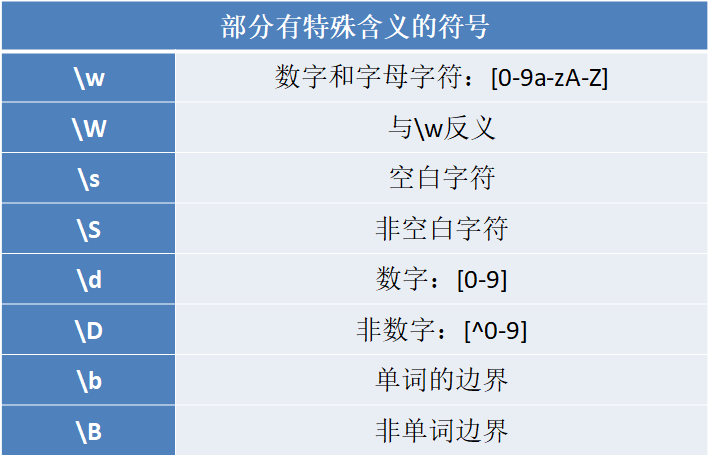
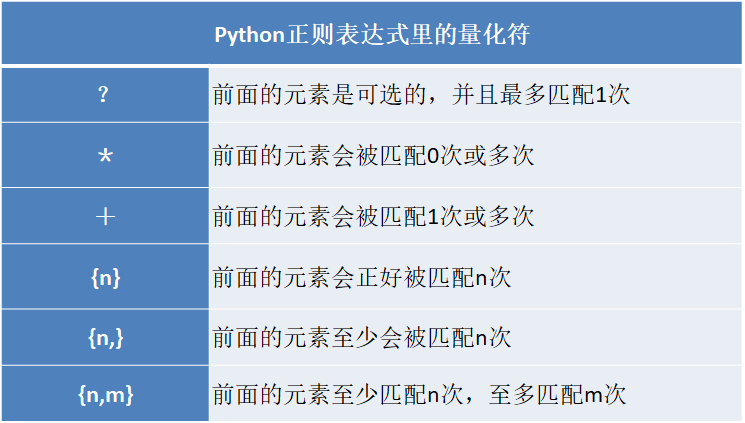
常用广义化符号
1、英文句号“.”:能代表除换行符“\n”任意一个字符;
2、字符类“[]”:被包含在中括号内部,任何中括号内的字符都会被匹配;
3、管道“|”:该字符被视为OR操作;
缺点: 使用正则表达式无法很好的定位特定节点并获取其中的链接和文本内容,而使用Xpath和Beautiful Soup能较为便利的实现这个功能。
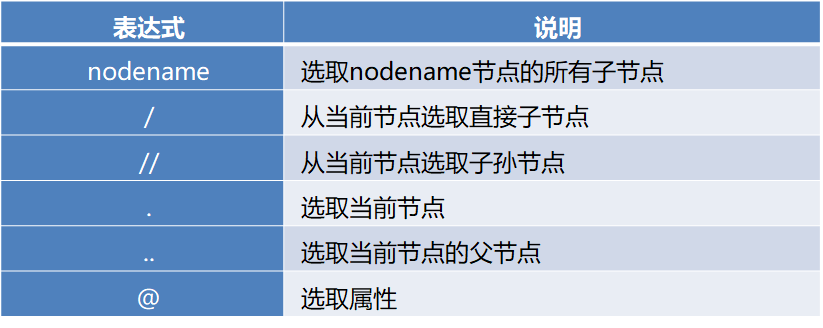
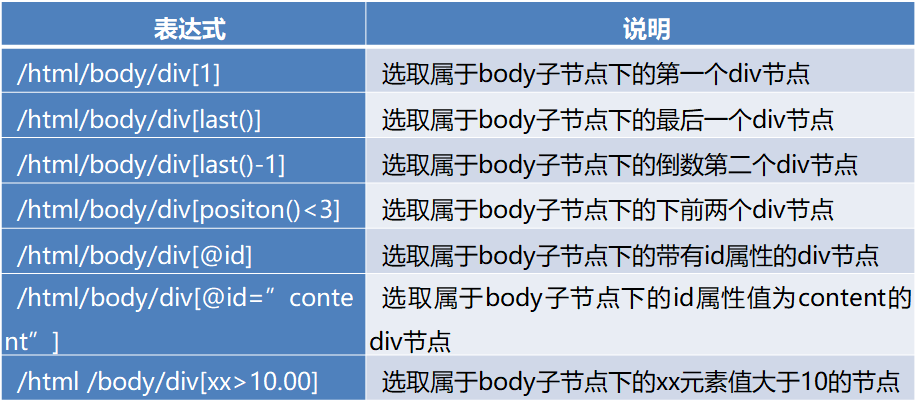
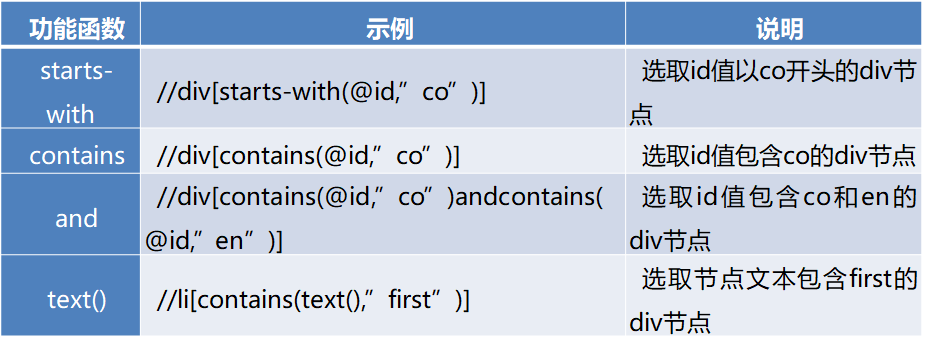
2.2 xpath库
用法:
示例:
import requests from lxml import etree # 发起http请求 url = 'http://www.tipdm.com/tipdm/index.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE' } rqq = requests.get(url,headers=headers) rqq.encoding = 'utf-8' print('实体:', rqq.text) # 将得到的网页内容解析成xml dom = etree.HTML(rqq.text, etree.HTMLParser(encodeing="utf-8")) #通过xpath获取指定节点的数据 list_a = dom.xpath("//*[@id='tddt']/div[2]/ul[1]/li/div[2]/a/@href")
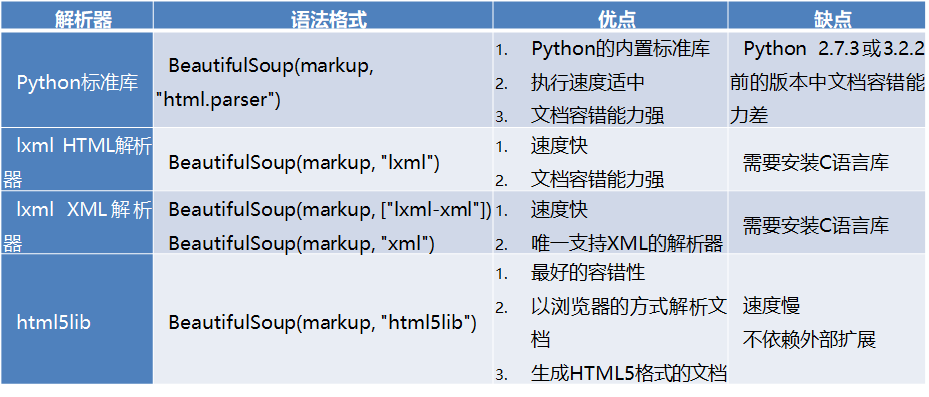
2.3 Beautiful soup库
示例:
from bs4 import BeautifulSoup import requests import pandas as pd from sqlalchemy import create_engine # 创建数据库连接引擎 engine = create_engine("mysql+pymysql://root:xq4077@127.0.0.1:3306/crawler?charset=utf8") # 发起http请求 rsp = requests.get("http://www.tipdm.com/") # 解析网页 soup = BeautifulSoup(rsp.content, "lxml") # 获取指定节点数据,处理数据 doms = soup.select("#menu>li>a") url = [i["href"] for i in doms] text = [i.text for i in doms] data = pd.DataFrame({"title": text, "url": url}) print(data) # 存入数据库 data.to_sql("tipdm", con=engine, if_exists="replace", index=False)
| 标题: | Python 爬虫总结 |
|---|---|
| 链接: | https://www.fightingok.cn/detail/21 |
| 更新: | 2022-09-18 22:32:08 |
| 版权: | 本文采用 CC BY-NC-SA 3.0 CN 协议进行许可 |